Building Trust in High-Stakes RAG Systems
Operationalizing Trust in National Security Intelligence
Company
Primer AI
Role
Lead Product Designer
Timeline
June 2024 - August 2024
Overview
Operationalizing trust for National Security AI
I led the strategy and design of RAG-V, a claim-level verification system that bridges generative speed and mission-critical accuracy. By transforming "black box" summaries into auditable evidence, we solved the "hallucination barrier" for intelligence clients and established the new explainability standard across Primer's product suite.

The Challenge
"Hallucination is a non-starter."
For our National Security clients, Generative AI wasn't just an efficiency tool; it was a risk. While typical users might tolerate a 5-10% error rate, Intelligence Analysts cannot. A single hallucinated entity could compromise a mission.
Traditional RAG tools offered sentence-level citations. Our research proved this insufficient: an accurate sentence can still contain a hallucinated fact.

Note: Data is illustrative, based on trends from Ke et al. (2025).
Ke, Y. H., Jin, L., Elangovan, K., Abdullah, H. R., Liu, N., Sia, A. T. H., Soh, C. R., Tung, J. Y. M., Ong, J. C. L., Kuo, C.F., Wu, S.C., Kovacheva, V. P., & Ting, D. S. W. (2025, April 5). Retrieval augmented generation for 10 large language models and its generalizability in assessing medical fitness. Nature. https://www.nature.com/articles/s41746-025-01519-z
Goal
RAG-V was a prototype to validate one hypothesis: grounding every claim in source evidence is both technically feasible and essential for trust.
Research
Learning from Verification Behaviors
I studied how different groups handle evidence and attribution to create patterns that would feel both familiar and trustworthy:
Academic citations
Academic citation conventions use footnotes or inline citations to ground claims as a trusted pattern for linking evidence.
Intel analyst workflows
Intel analyst workflows rely on similar citations but emphasize excerpts and metadata (organization, author, timestamp) to validate and share information.

Citation example from Citation Machine
LLM product conventions
LLM product patterns from ChatGPT, Gemini, Claude, and Perplexity use hoverable chips for citations. However, these verify at sentence level, which still risks hallucination and makes it unclear which specific claim is supported.

Reference pattern from Perplexity

On-demand verification from Gemini
Insight
Existing patterns were insufficient. Analysts needed claim-level granularity, not sentence-level approximation.
Technical Proposal
How It Works
Working with ML researchers, we developed a pipeline that:
Breaks down generated text into individual claims
Cross-checks each claim against retrieved sources
Iteratively regenerates summaries until claims are verified
Visit Primer's Research to read more details
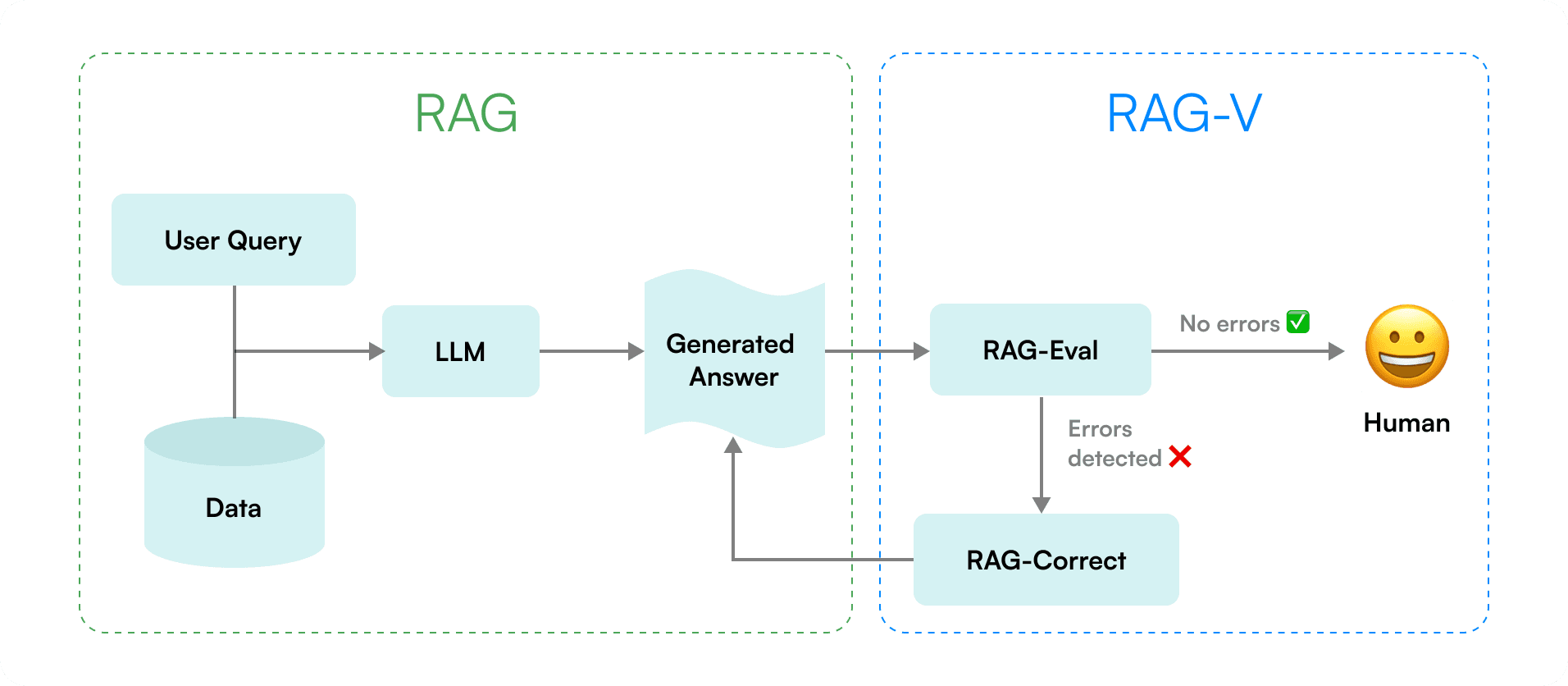
RAG-V pipeline illustration
Design Principles
Designing for scannability, transparency, and control
How might we give analysts the evidence they need to trust AI outputs without adding friction to their review process?
I established three core principles to make forensic verification usable without disrupting the analyst's high-velocity workflow.
Scannability Over Comprehensiveness
Analysts review dozens of documents at once. I designed highlighted verification indicators directly on the text.
Color-coded claim highlights allow users to scan for "Unverified" risks in seconds rather than reading every word.

Verification status as citation chip for scannability
Transparency for Trust Calibration
By explicitly exposing the model's limitations, we paradoxically increased user confidence. This trained analysts to treat the AI as a probabilistic partner rather than a black-box oracle.
Forensic Validation
To support this calibration, I designed a side-by-side interlock. Clicking a claim instantly scrolls the source document to the supporting evidence, allowing analysts to verify the AI's "work" without context switching.

Click to read source materials and verification details
Mitigating Information Loss
User feedback revealed a fear that the AI might "refine" the data too aggressively, scrubbing out relevant context along with the hallucinations.
Iterative Draft Visibility
I designed a recovery workflow that lets users toggle between draft versions. This functions as a safety net, giving analysts the power to review the "deleted scenes" and salvage removed information.

Review generation iteration through multiple drafts
Result
Trust Became the New Baseline
RAG-V achieved a significant reduction in unverified content and increased analyst confidence in generative features. Customers requested its extension beyond search summaries. It became the baseline explainability pattern across Primer products.
The prototype validation alone enabled contract renewals with customers who had previously blocked AI deployment. Cited as "best-in-class explainability" in competitive evaluations.
"This approach gives me much greater confidence in the accuracy of summaries! When can I expect to see RAG-V applied to other generative text beyond search summaries?"
— Intelligence analyst after RAG-V demo
Retrospective
Speed vs. Truth
Claim-level verification demonstrably built trust. Showing AI limitations increased credibility. Progressive disclosure solved latency challenges. While RAG-V's full claim-level verification was ultimately not adopted across all features due to cost and speed constraints, the principles and patterns I established became the foundation for Primer's new explainability standard.
Speed builds convenience, but transparency builds value. By exposing the model's "seams," we calibrated user trust for high-consequence decisions. This project shifted my thinking from designing features to designing systems that enable others. Ultimately, the reusable patterns and standards had a more lasting impact than any single interface.


